
Robots.txt-Generator






Über Robots.txt-Generator
Ein Robots.txt-Generator ist ein Online-Tool, das Websitebesitzern hilft, eine Robots.txt-Datei für ihre Website zu erstellen. Eine Robots.txt-Datei ist eine einfache Textdatei, die im Stammverzeichnis einer Website abgelegt wird, um Suchmaschinen-Crawlern und anderen automatisierten Agenten Anweisungen zum Crawlen und Indexieren der Seiten der Website zu geben.
Die Datei Robots.txt enthält eine Reihe von Regeln, die festlegen, welche Webseiten und Verzeichnisse von Suchmaschinen gecrawlt und welche ausgeschlossen werden sollen. Die Datei kann auch verwendet werden, um den Speicherort der Sitemap der Website und anderer wichtiger Dateien anzugeben.
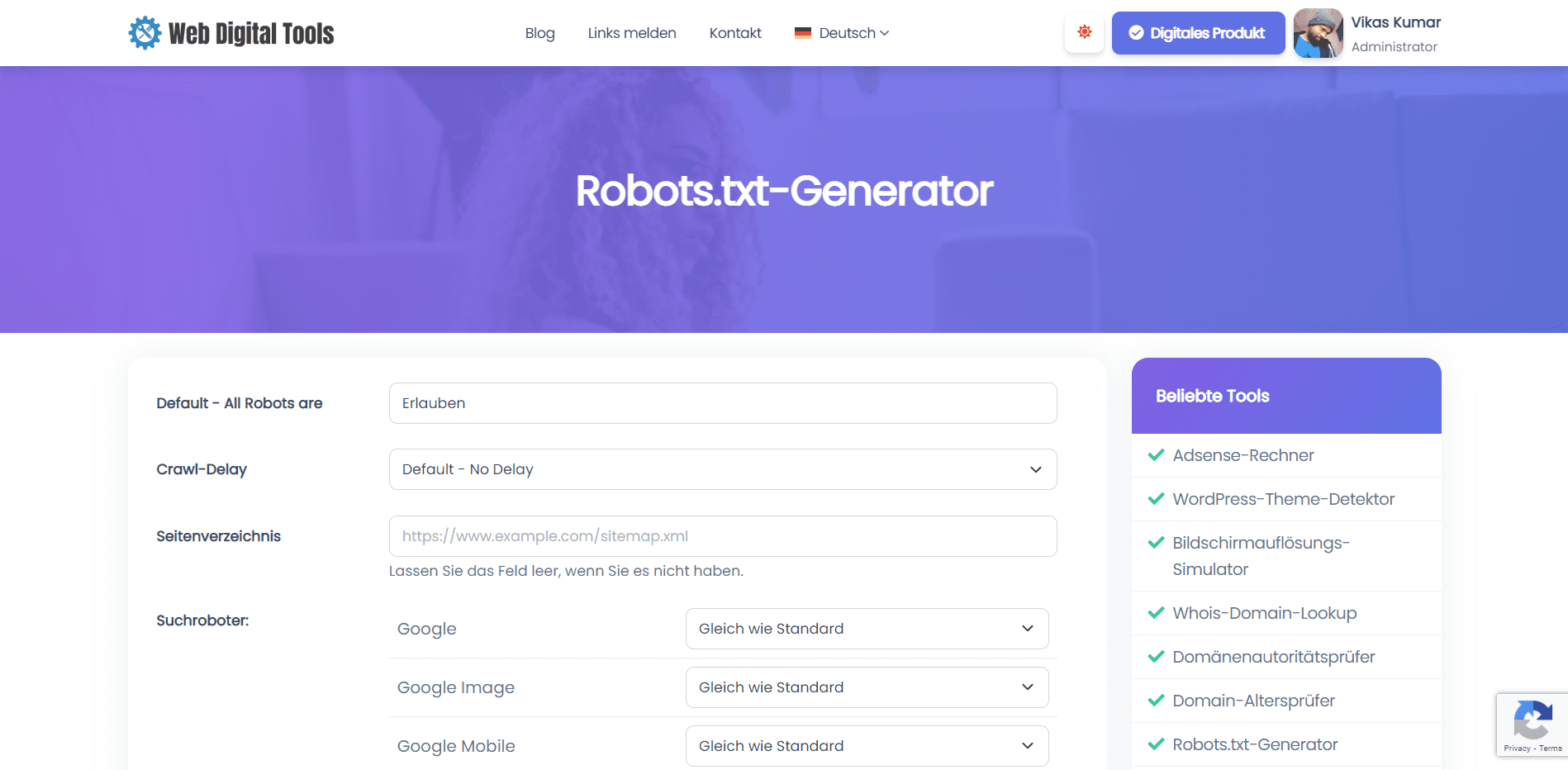
So verwenden Sie dieses Tool:
- Rufen Sie die Robots.txt-Generator-Tool-Seite auf.
- Geben Sie die Details Ihrer Website ein, z. B. die Website-URL, die Sitemap-URL und den Benutzeragenten, auf den Sie abzielen möchten.
- Passen Sie die Regeln für Ihre Robots.txt-Datei an, indem Sie beispielsweise angeben, welche Verzeichnisse und Seiten zugelassen oder nicht zugelassen werden sollen.
- Klicken Sie auf die Schaltfläche "Generieren", um die Robots.txt-Datei zu erstellen.
- Kopieren Sie den generierten Code und fügen Sie ihn in eine reine Textdatei mit dem Namen „Robots.txt“ ein und laden Sie sie in das Stammverzeichnis Ihrer Website hoch.
Das Tool „Robots.txt Generator“ kann ein nützliches Tool für Website-Besitzer sein, die sicherstellen möchten, dass ihre Website kontrolliert und effizient von Suchmaschinen gecrawlt und indexiert wird. Durch die Verwendung des Tools zum Erstellen einer benutzerdefinierten Robots.txt-Datei können Website-Eigentümer sicherstellen, dass Suchmaschinen auf die wichtigsten Seiten ihrer Website zugreifen können, und gleichzeitig doppelte Inhalte, Seiten von geringer Qualität und andere Probleme vermeiden, die ihre SEO-Leistung beeinträchtigen können .
Syntax & Direktiven verstehen
Das Verständnis der Syntax und Anweisungen in einer Robots.txt-Datei ist wichtig für Websitebesitzer, die eine Robots.txt-Datei mit einem Robots.txt-Generatortool erstellen oder eine vorhandene Robots.txt-Datei bearbeiten möchten.
Die Syntax einer Robots.txt-Datei ist relativ einfach. Jede Zeile der Datei besteht aus einem Benutzeragentennamen, gefolgt von einer oder mehreren Anweisungen. Der Name des Benutzeragenten gibt die Suchmaschine oder den Crawler an, für die die Anweisungen gelten. Die Direktiven geben an, welche Seiten und Verzeichnisse für den Benutzeragenten zugelassen oder nicht zugelassen werden sollen.
Die häufigsten Anweisungen in einer Robots.txt-Datei sind:
-
User-Agent: Dies gibt die Suchmaschine oder den Crawler an, für die die Anweisungen gelten. Wenn Sie eine Anweisung auf alle Suchmaschinen und Crawler anwenden möchten, verwenden Sie ein Sternchen (*) als Namen des Benutzeragenten.
-
Disallow: Dies gibt an, welche Seiten oder Verzeichnisse nicht von dem angegebenen Benutzeragenten gecrawlt werden sollen. Sie können die Disallow-Direktive verwenden, um bestimmte Seiten oder Verzeichnisse von Suchmaschinen-Ergebnisseiten auszuschließen.
-
Zulassen: Dies gibt an, welche Seiten oder Verzeichnisse vom angegebenen Benutzeragenten gecrawlt werden sollen. Sie können die Allow-Direktive verwenden, um bestimmte Seiten oder Verzeichnisse zuzulassen, die andernfalls durch eine Disallow-Direktive blockiert würden.
-
Sitemap: Dies gibt den Speicherort der Sitemap der Website an. Die Sitemap ist eine Datei, die alle Seiten der Website auflistet, die der Eigentümer von Suchmaschinen indizieren möchte.
-
Crawl-Verzögerung: Dies gibt die Verzögerung in Sekunden an, die der angegebene Benutzeragent zwischen aufeinanderfolgenden Anfragen an die Website warten soll. Die Crawl-Delay-Direktive kann verwendet werden, um die Rate zu begrenzen, mit der Suchmaschinen die Website crawlen, was für Websites mit begrenzten Serverressourcen nützlich sein kann.
Es ist wichtig zu beachten, dass bei der Syntax und den Anweisungen einer Robots.txt-Datei zwischen Groß- und Kleinschreibung unterschieden wird. Darüber hinaus interpretieren einige Suchmaschinen die Anweisungen möglicherweise anders, daher ist es eine gute Idee, die Robots.txt-Datei mit einem Robots.txt-Prüftool zu testen, um sicherzustellen, dass sie wie beabsichtigt funktioniert.
Lassen Sie uns unser Robots.txt-Generator-Tool ausprobieren und uns melden, wenn Sie Fehler gefunden haben.
